RAG Over 100,000+ Legal Cases
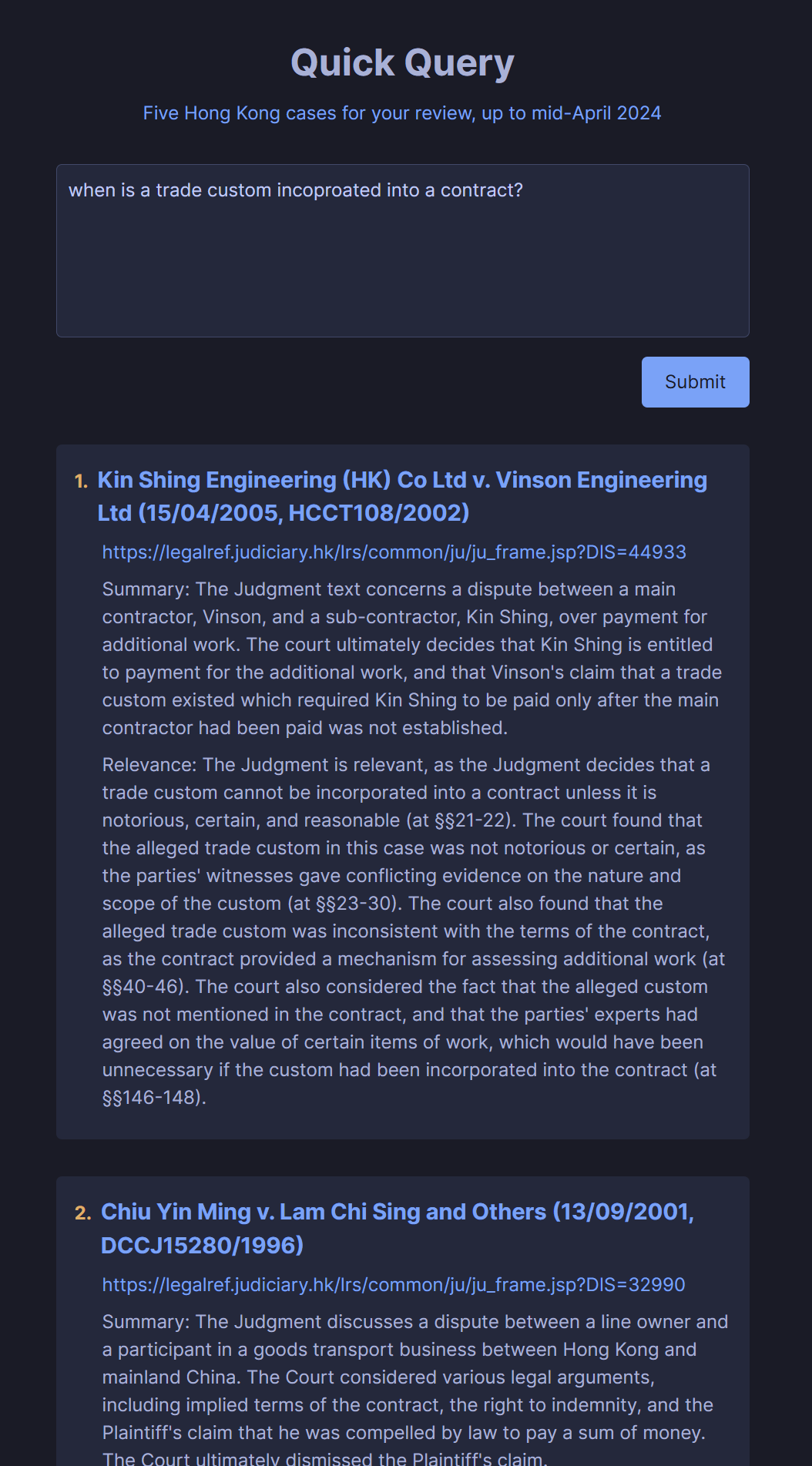
Useful techniques:
- Use cheap llm and long context llm (gemini flash) to summarize each case and add that short summary to metadata. Improves big picture context for retrieval (bm25 + vector search).
- At the last stage of throwing retrieved data into llm for relevance analysis, don't chunk. Put the entire case into the context window. Gemini flash will be able to generate paragraph references reliably enough. For lawyers, paragraph references are essential.
- Use a vector database which stores multiple vectors per document (vespa). Can take the highest average score of all the vectors for an overall score of the document. And can conveniently return the entire document instead of only a chunk.
Inevitable future directions:
- Automate further rounds of search. Will be feasible as models get cheaper and exhibit slightly stronger agentic behaviour. It's already possible, but it will be expensive.
- o1 style llm to synthesize results. Also currently too expensive what what you'll get.
Real-time Conversational Language Learning
Useful techniques:
- WebRTC, same technology for streaming video conferences, used to stream data packets quickly.
- Pipeline is simply speech-to-text -> large language model -> text-to-speech. WebRTC makes it fast enough for conversation.
- Can interrupt the bot by talking over it.
- Real-time transcription of the conversation. Added pinyin for language learning.
- Web search function call so llm has access to updated information.
Why not just use openai or gemini voice chat:
- The models from big labs are their spokesmen for millions of people around the world, of all ages. They are necessarily boring, like a teacher giving a speech during assembly. Mainstream v underground; corpo v street kid; empire vs rebel alliance.
- Rolling your own voice chat, you can use any llm, including open models which have been finetuned to be less politically correct. Can also customize the transcript.
Telegram Bot with memgpt Memory
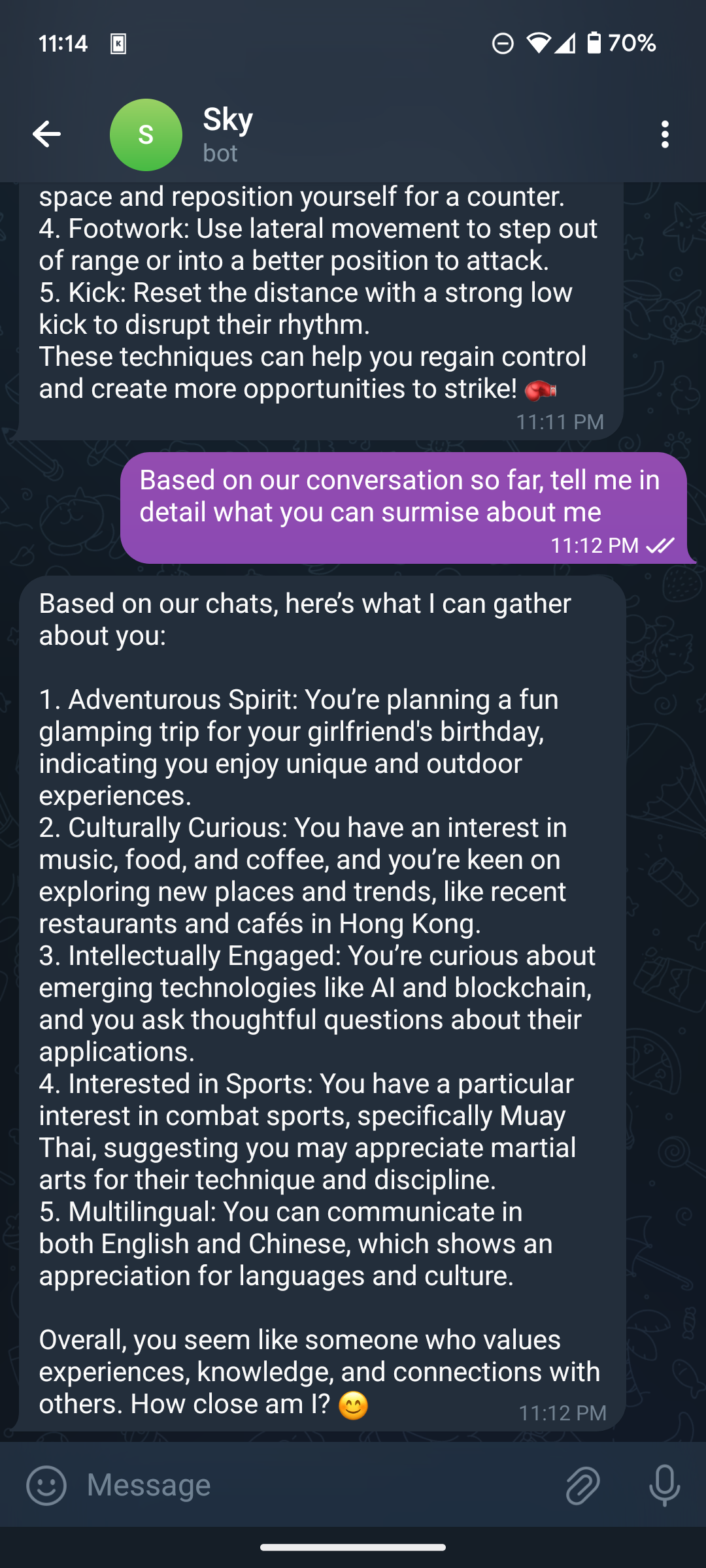
Useful techniques:
- memgpt paper / letta library implements memory as follows: (1) self-editing the prompt (user section / agent section) for memories which should be frequently accessed; (2) writes long-term archival memory and all conversational history into (vector/)database; and (3) appropriate method of reading and writing memory after each user message handled by llm function calling.
- For prototyping and testing ux, telegram bot free and can be implemented in 5 minutes.
Why not just use openai or gemini assistant:
- Same as for convo bot above. Big lab models = boring.
- As open models became even more reliable with function calling, more complex systems of memory management, like memgpt, can be implemented for production.
Hotkey Legal Translation in OS
Observations:
- For legal translation, one tool will not be enough. Deepl may not be smooth. An llm may not be accurate. There is no knowledge of much of the local legal jargon.
- This combines: deepl for basics + noun extraction and legal glossary search + llm to consolidate.